1. 보험 개요
1) 보험 종류
-1 생명보험
(a) 상부상조 정신을 바탕으로 출생 및 사망 등의 불의의 사고로 인한 경제적 손실을 보전하기 위한 준비제도
(생명보험협회)
-2 손해보험
(a) 우연한 사건으로 발생하는 재산상의 손해를 보상하여, 경제생활의 불안정을 제거 또는 경감해주는 상품
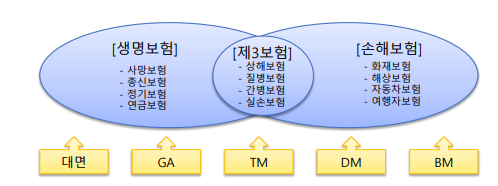
2) 계약의 체결
-1 기본용어
(a) 보험료 : 보험계약자가 보험회사에 납부
(b) 보험금 : 보험회사가 보험계약자에게 지급
(c) 계약자 : 보험계약을 체결하고 보험료를 지급할 의무가 있는 자
(d) 피보험자 : 보험사고가 발생하였을 때에 보험금을 지급받을 자 (손해보험),
생명과 신체가 보험에 가입된 자연인(생명보험)
(e) 수익자 : 보험금을 지급받을 자
-2 계약체결 과정
(a) 대체로 보험계약자가 청약서를 작성하여 보험설계사나 보험대리점에 제출
(b) 이에 대하여 보험회사가 승낙을 함으로써 계약이 체결
(c) 이후 보험증권을 교부
2. 언더라이팅
1) 언더라이팅 개요
-1 언더라이팅(계약심사) 의미
(a) 협의 : 보험 회사의 위험 선택업무 즉, 위험평가의 체계회된 기법
(b) 광의 : 보험계약의 모집과정부터 계약인수 및 처리, 손해사정 및 보험지급까지의 모든 과정의 체계화된 기법
-2 언더라이터 : 언더리이팅하는 업무 담당자 또는 보험업자
-3 역선택
(a) 보험가입자 : 미래 위험 발생 가능성이 있거나 그 정도가 높은 사람 또는 물건 등
(b) 손해 발생 : 보험 상품을 만들 때 정해진 보험료보다 보험금이 더 많은 경우
(c) 역선택 : 보험 계약 전 계산된 위험보다 높은 집단이 가입하여 피보험 단체의 사고발생확률을 증가시키는 것
-4 인공지능 활용 포인트
(a) 계약심사 과정의 비용절감
(b) 계약 심사 과정의 신속화
(c) 계약심사 정확도 향상
(d) 역선택 탐지
--> 인공지능을 활용한 엉더라이팅 자동화
A생보사 : 자동 언더라이팅으로 자동화, 고객으로부터의 서류 제출과 정보 수집 절차 간소화
B생보사 : 인공지능과 가입심사 규칙 시스템 결합
C생보사 : 청약서 이미지와 영업, 계약 등의 단계에서 수집된 정보로 자동 승낙
D생보사 : 자연어 학습 기반의 머신러닝 언더라이팅 자동화 시스템 구축 특허 획득
-5 D생보사의 인공지능 활용 예시
(a) 데이터 수집 : 보험설계사가 질문하고 고객이 답변한 사전 질문서, 고객의 연령, 직업, 과거 심사정보,
보험 가입이력
(b) 데이터 전처리 : 질문서의 비정형 텍스트 벡터화 , 과거 심사정보 벡터화, 보험 가입이력 벡터화
(c) 표준 미달 가능성, 승인 거절 가능성 계산
(d) 자동 심사결과 영향도 분석 (변수 중요도)
2) 서비스 구현 예시
-1 서비스 구현 기획
(a) 서비스 정의 : 보험 계약체결 후 인수 심사를 위한 지표(Score) 생성
(b) 데이터셋 : 고객정보, 가입정보, 모집설계사 정보, 챗봇 설문지
(d) 데이터셋 수집 : 내부 데이터
(e) 데이터 예제
1. 계약자 및 피보험자 정보
2. 주보험 상품명, 보험기간, 납입기간, 납입주기, 납입보험료, 납입방법
3. 모집인명, 모집인코드, 모집인 입사일자, 모집인 근속년수
4. 심사점
-2 서비스 구현 기술
(a) 저장 (스토리지 / 데이터 레이크)
(b) 빅데이터 및 분석
(c) 머신러닝 프로그래밍 언어
(d) 머신러닝 프레임워크, 라이브러리
(e) 머신러닝 플랫폼 서비스
(f) 데이터 시각화

3) 인공지능 활용의 한계
-1 프로파일링 대응권
(a) 소비자가 보험사 등에 자동화된 언더라이팅 결과, 신용평가 결과, 대출 거절 등에 관해 설명을 요구하고 이의를
제기할 수 있는 제도
-2 인공지능 모델의 해석과 한계
(b) 거절된 계약에 대해 사유 요청 시 안내나 설명이 불가하거나 어려움
-3 동의 데이터 부족
'핀테크 인공지능' 카테고리의 다른 글
| 금융상품 추천 (15) | 2024.09.15 |
|---|---|
| 데이터 유형별 전처리 (이미지) (1) | 2024.09.14 |
| 데이터 유형별 전처리 (시계열) (5) | 2024.09.14 |
| 데이터 유형별 전처리 (정형) (0) | 2024.09.14 |
| 데이터 수집과 전처리 (4) | 2024.09.14 |













































































